Preprocessing#
Training ntuples are produced using the training-dataset-dumper which dumps them directly into hdf5 files. However, the training ntuples are not yet optimal for training the different b-taggers and require preprocessing. The configuration of the preprocessing is done with a .yaml file which steers the whole preprocessing. An example can be found here. The different parts of the config file will be explained in the different steps of the preprocessing.
Currently one can also use Umami PreProcessing (UPP) module using the same preprocessing commands but a somewhat different config. The documentation can be found here. An example of a config please see examples/preprocessing/PFlow-Preprocessing-UPP-DL1r.yaml.
Currently one can also use Umami PreProcessing (UPP) module using the same preprocessing commands but a somewhat different config. The documntation can be found here. An example of a config please see examples/preprocessing/PFlow-Preprocessing-UPP-DL1r.yaml.
Motivation#
The motivation for preprocessing the training samples results from the fact that the input datasets are highly imbalanced in their flavour composition. While there are large quantities of light jets, the fraction of b-jets is small and the fraction of other flavours is even smaller. A widely adopted technique for dealing with highly unbalanced datasets is called resampling. It consists of removing samples from the majority class (under-sampling) and / or adding more examples from the minority class (over-sampling). In under-sampling, the simplest technique involves removing random records from the majority class, which can cause loss of information. Another approach can be to tell the network how important samples from each class are. For e.g. a majority class you can reduce the impact of samples from this class to the training. You can do this by assigning a weight to each sample and use it to weight the loss function used in the training.
Hybrid Samples#
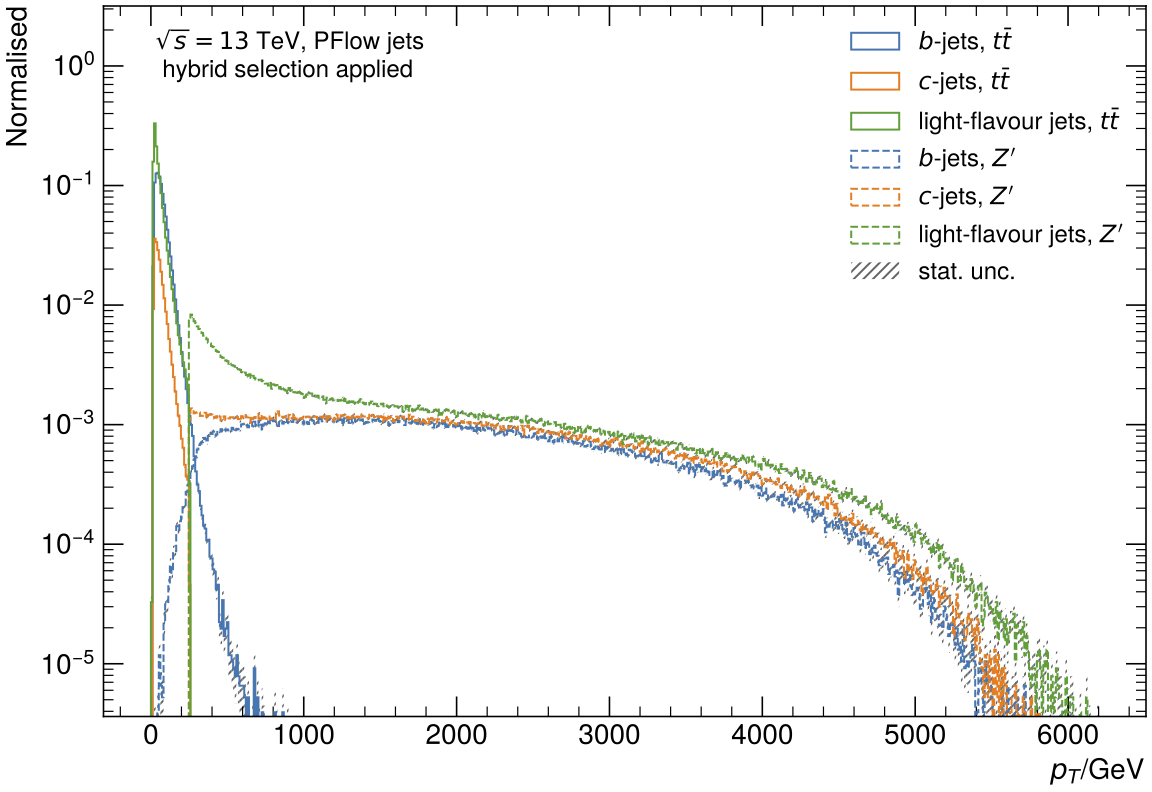
Umami/DIPS and DL1r are trained on so-called hybrid samples which are created using both t\bar{t} and Z' input jets.
The hybrid samples for PFlow jets are created by combining events from t\bar{t} and Z' samples based on a pt threshold, which is defined by the pt_btagJes variable for all jet-flavours.
Below a certain pt threshold (which needs to be defined for the preprocessing), t\bar{t} events are used in the hybrid sample. Above this pt threshold, the jets are taken from Z' events.
The advantage of these hybrid samples is the availability of sufficient jets with high pt, as the t\bar{t} samples typically have lower-pt jets than those jets from the Z' sample.
The production of the hybrid samples in the preprocessing stage requires preparation of input files which are created from the training ntuples.
Additional preprocessing steps for PFlow jets are required to ensure similar kinematic distributions for the jets of different flavours in the training samples in order to avoid kinematic biases. One of these techniques is downsampling which is used in the Undersampling approach.
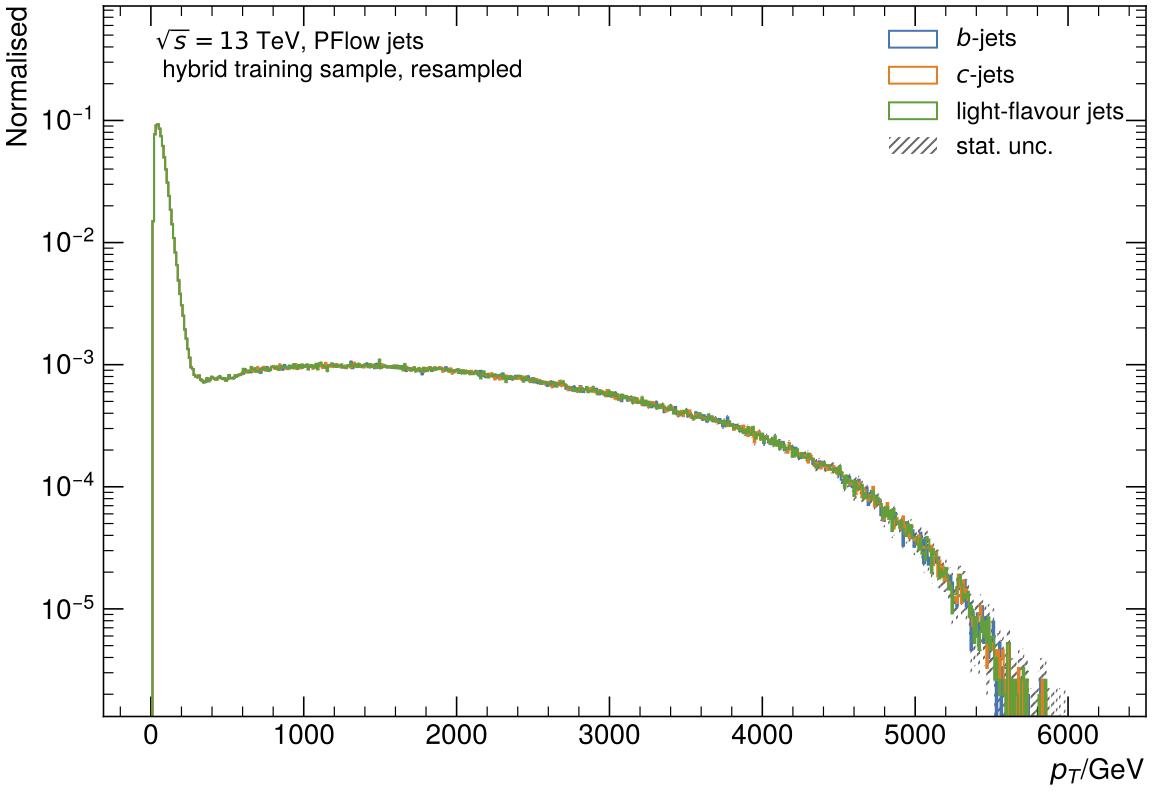
Although we are using here for example reasons t\bar{t} and Z' to create a hybrid sample, you can use any kind of samples. Also, you don't need to create a hybrid sample. You can still use only one sample and for the preprocessing.
All these steps are implemented in the preprocessing.py script, whose usage is described in the follwing documentation.
Preprocessing Steps#
For the preprocessing, four steps need to be done:
- Preparation step: Extract the different flavours from the
.h5files from the training-dataset-dumper and separate them into flavour-specific files. Also the the split in training/validation/evaluation is done at this step. - Resampling step: Combine and resample the different processes/flavours to achieve similar p_T and \eta distributions for all used flavours.
- Scaling/Shifting step: Calculate scaling/shifting values for all variables that are about to be used in the training.
- Writing step: Apply the scaling/shifting and write the final training sample to disk. In this step, the collections of jets and track variables are encoded and flattened so that we can load/use them for training.
Apply Preprocessing with stand-alone script#
In some cases you might want to apply the scaling and shifting to a data set using a stand-alone script. For instance if you train with pytorch and just need a validation/test sample.
This can be done with the script scripts/process_test_file.py.